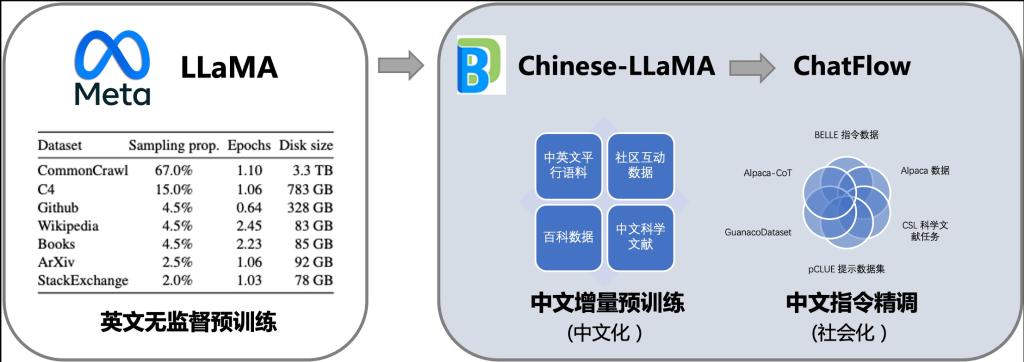
伶荔中文大语言模型,基于全球首个模块化大模型预训练框架TencentPreTrain(下载量10万/月,发表在自然语言处理顶会ACL 2023),是首个中文开源7B、13B、30B大模型。
其核心技术包括:(1)LLaMA 中文预训练、指令微调及问答;(2)自适应数据采样的语言迁移学习;(3)英文 → 中英文平行语料训练;(4)自适应调整训练比例,解决知识遗忘和迁移。
目前,伶荔中文大语言模型已在以下场景得到应用:
1.百度云智能千帆大模型平台,提供API调用。
2.中文金融知识大模型聚宝盆(Cornucopia),与中科院成都计算机应用研究所 (中科信息)联合开发,基于伶荔微调构建。
3.云泥科技Unique角色扮演大模型,基于伶荔微调,能实现特定的对话风格。
4.伶荔数字人,包括伶荔驱动对话,虚拟主播等。
5.数字客服,包括系统运维、客户咨询、产品咨询,已在中广核、电信、移动、深大信息中心等场景得到应用。